
يُعتبر Apache Hadoop إطار عمل برمجي مفتوح المصدر والذي يدعم التطبيقات الموزعة للبيانات الكثيفة، ومرخص وفقاً لرخصة Apache v2. كما أنه يدعم تشغيل التطبيقات على مجموعات كبيرة من الأجهزة السلعية. وقد تم اشتقاق Hadoop من معمارية MapReduce الخاصة بجوجل وأبحاث نظام ملفات جوجل (GFS).
يوفر إطار Hadoop كلاً من الموثوقية وحركة البيانات للتطبيقات. ويقوم Hadoop بتنفيذ نموذج حسابي يُدعي MapReduce، حيث تقسم فيه التطبيقات إلى العديد من الأجزاء الصغيرة للعمل، كل واحدة منها قد تنفذ أو يعاد تنفيذها على أية عقدة موجودة في الكتلة. وبالإضافة لذلك، فإنه يوفر نظام ملفات موزع يقوم بتخزين البيانات على عقد الحساب، مما يوفر درجة عالية جداً لعرض معدل الحركة الكلي عبر الكتلة. هذا وقد صمم كلاً من map/reduce ونظام الملفات الموزع بحيث تعالج مشكلة فشل العقدة تلقائياً من قبل الإطار. بحيث يقوم بتمكين التطبيقات من العمل مع الآلاف من الحواسب المستقلة وبيتابايت من البيانات. هذا وتتكون "منصة" Apache Hadoop حالياً بشكل عام من نواة Hadoop، و MapReduce ونظام ملفات Hadoop الموزع (HDFS)، بالإضافة إلى عدد من المشاريع المتعلقة بما فيها Apache Hive وApache Hbase وغيرهم الكثير.
الجدير بالذكر أن Hadoop قد كتب بلغة البرمجة "جافا"، كما أنه يُعد أحد مشاريع أباتشي الرائدة التي بنيت واستخدمت من قبل مجتمع عالمي من المساهمين. ويمتلك Hadoop والمشاريع المتعلقة به (Hive، Hbase، Zookeeper ..وهلم جرا) العديد من المساهمين عبر الشركات البرمجية العالمية. وبرغم أن أكواد الجافا هي الأكثر شيوعاً، إلا أنه يمكن استخدام أي لغة برمجة مع عملية "التدفق" لتنفيذ أجزاء "map" و "reduce" الخاصة بالنظام.
تاريخ Apache Hadoop
لقد أنشيء Hadoop من قبل "دوغ كاتينغ" و "مايك كافاريلا" عام 2005. وقد أسماه دوغ، الذي كان يعمل في ياهو في ذلك الوقت، تيمناً بالفيل اللعبة الخاص بابنه. كما أن عملية التطوير كانت نابعة في الأساس لدعم توزيع مشروع محرك البحث Nutch.
المعمارية
يتكون Hadoop من Hadoop Common والذي يوفر الدخول إلى أنظمة الملفات المدعومة من قبل Hadoop. وتحتوي حزمة Hadoop Common على ملفات أرشيف الجافا (JAR) الضرورية والبرمجيات المطلوبة لبدء Hadoop. كما توفر الحزمة أيضاً شفرة المصدر، والتوثيق، وقسم المساهمة الذي يشمل مشاريع Hadoop Community.
ومن أجل إقامة جدولة فعّالة للعمل، فإن كل نظام ملفات متوافق مع Hadoop يجب أن يوفر معرَّف للموقع: اسم الرف (على نحو أدق، مفتاح الشبكة) الذي تتواجد فيه عقدة العامل. ويمكن لتطبيقات Hadoop استخدام هذه المعلومات لتشغيل العمل على العقدة التي توجد فيها البيانات، وإذا تعذر ذلك، فستكمل على نفس الرف/المفتاح، مما يحد من الحمل الأساسي. ويستخدم نظام ملفات Hadoop الموزع (HDFS) هذه الطريقة عند تكرار البيانات وذلك للحفاظ على النسخ المختلفة من البيانات على رفوف مختلفة. والهدف هنا هو الحد من تأثير انقطاع التيار أو أعطاب مفتاح الطاقة، وبذلك حتي في حالة حدوث هذه الأمور، فإن البيانات قد تكون لا تزال قابلة للقراءة.
يشمل عنقود Hadoop صغير على عقدة واحدة رئيسية وعقد عاملة متعددة. وتتكون العقدة الرئيسية من متعقب الوظيفة (JobTracker)،ومتعقب المهمة (TaskTracker)،و عقدة الاسم (NameNode)، وعقدة البيانات (DataNode). وتتصرف العقدة التابعة أو العاملة مثل عقدة البيانات و متعقب المهمة، على الرغم من إمكانية الحصول على عقد عاملة للبيانات فقط وعقد عاملة للحساب فقط. وهذه عادة ما تُستخدم فقط في التطبيقات غير القياسية. ويتطلب Hadoop بيئة الجافا Java Runtime Environment 1.6 أو أعلى. كما تتطلب برمجيات التشغيل والإغلاق القياسية صدفة آمنة (ssh) تجهز بين العقد الموجودة في العنقود.
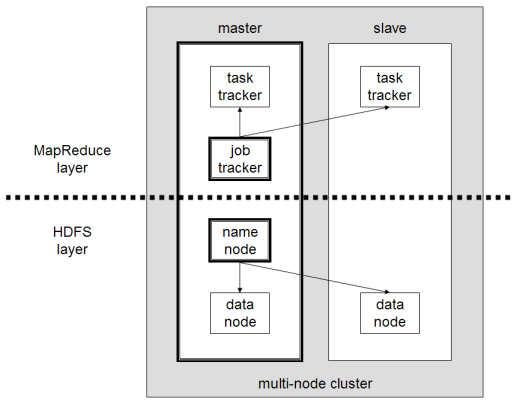
عنقود Hadoop متعدد العقد
وفي العناقيد الأكبر، يدار نظام ملفات Hadoop الموزع (HDFS) عبر خادوم NameNode مخصص لاستضافة قائمة نظام الملفات، و NameNode ثانوي يمكنه توليد لقطات مصورة لهيكل الذاكرة الخاصة بـ NameNode، وبالتالي يتلافى إتلاف نظام الملفات والحد من فقدان البيانات. وبالمثل، فإن خادوم JobTracker المستقل يمكنه إدارة جدولة الوظائف. وفي العناقيد التي يكون فيها محرك Hadoop MapReduce منتشر ضد نظام الملفات البديل، فإن معمارية NameNode الأساسي و NameNode الثانوي و DataNode الخاصة بنظام ملفات Hadoop الموزع يتم استبدالها من قبل نظام ملفات خاص معادل لها. وقد أشار الإحصائي البارز "جو تونر" إلى Hadoop بأنه "تيرا داتا الخاصة بالرجل الفقير"( تيراداتا هي شركة عملاقة متخصصة في بيع برامج قواعد البيانات وتحليل الاحصائيات).
أنظمة الملفات
نظام ملفات Hadoop الموزع
إن HDFS هو نظام ملفات موزع، ومحمول وقابل للتطوير مكتوب بلغة جافا من أجل إطار Hadoop. وكل عقدة في نموذج Hadoop تمتلك عادة عقدة اسم (NameNode) فردية، وكتلة من عقد البيانات (DataNodes) لتشكيل كتلة نظام ملفات Hadoop الموزع. ويعتبر هذا هو الوضع الطبيعي، لأن كل عقدة لا تحتاج عقدة بيانات كي تكون متواجدة. وتعمل كل عقدة بيانات على سد البيانات عبر الشبكة باستخدام بروتوكول TCP/IP من أجل الاتصال. ويستخدم العملاء إجراء الاتصال عن بعد (RPC) للتواصل مع بعضهم البعض. هذا ويقوم نظام ملفات Hadoop الموزع بتخزين الملفات الكبيرة (الحجم المثالي للملف هو من مضاعفات الرقم 64 ميجا بايت) عبر آلات متعددة. كما يحقق الموثوقية عن طريق تكرار البيانات عبر استضافات متعددة، وبالتالي لا يحتاج إلى التخزين على صف مكرر من الأقراص المستقلة RAID على الاستضافات. ومع قيمة النسخ المتماثل الافتراضية، 3، يتم تخزين البيانات على ثلاثة عقد: اثنين على نفس الرف، وواحدة على رف مختلف. ويمكن لعقد البيانات التواصل مع بعضها البعض لإعادة توازن البيانات، ونقل النسخ، وللحفاظ على النسخ المتماثل للبيانات بكفاءة عالية. كما أن نظام ملفات Hadoop الموزع لا يتوافق مع معايير (POSIX) بشكل كلي، لأن متطلبات POSIX تختلف عن الأهداف المستهدفة لتطبيق Hadoop. هذا وقد صمم نظام ملفات Hadoop الموزع للتعامل مع الملفات الكبيرة جداً.
لقد أضاف نظام ملفات Hadoop الموزع مؤخراً قدرات توافر عالية، مما يسمح لخادم البيانات الوصفية الرئيسي (NameNode) بأن يقوم بتجاوز الفشل من أجل عمل نسخة احتياطية في حالة الفشل. كما يتم تطوير تجاوز الفشل التلقائي أيضاً. وبالإضافة لذلك، فإن نظام الملفات يتضمن ما يسمي بـ NameNode الثانوي، وهو ما قد يضلل بعض الناس بالتفكير بأنه في حالة توقف NameNode الرئيسي فإن NameNode الثانوي يتسلم مقاليد الأمور. ولكن في الحقيقة، يقوم NameNode الثانوي بالاتصال مع NameNode الرئيسي ويبني لقطات مصورة من معلومات الدليل الخاصة بـ NameNode الرئيسي، والتي يتم حفظها بعد ذلك في مسارات محلية أو مسارات بعيدة. ويمكن استخدام صور نقاط التفتيش هذه لإعادة تشغيل NameNode الرئيسي المُعطل بدون الحاجة إلى إعادة تشغيل دفتر اليومية الكامل لإجراءات نظام الملفات، ثم تحرير السجل لإنشاء اختصار مباشر حديث. ولأن NameNode هو نقطة واحدة للتخزين وإدارة البيانات الوصفية، فإنه يمكن أن يكون عنق الزجاجة لدعم عدد كبير من الملفات، وخاصة الأعداد الكبيرة من الملفات الصغيرة. ويعتبر اتحاد نظام ملفات Hadoop الموزع هو إضافة جديدة تهدف إلى معالجة هذه المشكلة لحد ما، وذلك من خلال السماح لعدد من الأسماء المتعددة بأن تخدم عن طريق NameNodes منفصلة.
ومن أهم مميزات استخدام نظام ملفات Hadoop الموزع هو توفير وعي بالبيانات بين متعقب الوظيفة ومتعقب المهمة. فمتعقب الوظيفة يقوم بجدولة الخريطة أو تقليل الوظائف بالنسبة لمتعقب المهمة مع وجود وعي بموقع البيانات. ومثال على هذا، إذا كانت العقدة A تحتوي على البيانات (X, Y, Z) والعقدة B تحتوي على البيانات (a, b, c). بعد ذلك، سيقوم متعقب الوظيفة بجدولة العقدة B لتنفيذ خريطة أو تقليل المهام على (a, b, c) والعقدة A قد يتم جدولتها لتنفيذ خريطة أو تقليل المهام على (X, Y, Z). وهذا يقلل كمية البيانات التي تمر عبر الشبكة ويمنع نقل البيانات غير الضرورية. وعندما يتم استخدام Hadoop مع ملفات الأنظمة الأخري، فإن هذه الميزة لا تكون متوفرة دائماً. وهذا يمكن أن يكون له تأثير كبير على وقت إنجاز الوظيفة، وهو ما أثبت عند إجراء وظائف البيانات المكثفة.
لقد صمم نظام ملفات Hadoop الموزع لمعظم الملفات غير القابلة للتغير وربما يكون غير مناسب للأنظمة التي تتطلب عمليات كتابة متزامنة. والتقييد الآخر لنظام ملفات Hadoop الموزع هو أنه لا يمكن تحميله مباشرة بواسطة نظام التشغيل الموجود. حيث أن إدخال وإخراج البيانات من نظام ملفات Hadoop الموزع، هي عملية تحتاج عادة أن يتم أداءها قبل وبعد تنفيذ المهمة، وهو أمر ربما يكون غير مريح. ولقد طوّر نظام الملفات الافتراضي (FUSE) لمعالجة هذه المشكلة، على الأقل بالنسبة لنظام لينكس وأنظمة يونكس الأخري.
ويمكن تحقيق عملية الوصول إلى الملفات من خلال واجهة جافا الأصلية، وواجهة Thrift لتوليد عميل بلغة من اختيار المستخدمين (C++، جافا، بيثون، PHP، روبي، Erlang، بيرل، هاسكل، C#، Cocoa، Smalltalk و Ocaml)، واجهة الأوامر، أو تصفحها من خلال تطبيق الويب الخاص بواجهة نظام ملفات Hadoop الموزع عبر HTTP.
أنظمة الملفات الأخري
بحلول مايو 2011، شملت لائحة أنظمة الملفات المدعومة:
HDFS: نظام ملفات Hadoop الخاص المتعرف على الرفوف، والذي صمم لجدولة عشرات بيتابايت من مساحة التخزين وللعمل على رأس أنظمة الملفات التي تقع تحت أنظمة التشغيل.
نظام ملفات Amazon S3: ويستهدف هذا النظام في الكتل المُستضافة على البنية التحتية لخادوم Amazon Elastic Compute Cloud. ولا يوجد أي رفوف في هذا النوع من أنظمة الملفات، فكل ما فيه يتم عن بعد.
CloudStore: (والذي كان يُعرف سابقاً باسم نظام كوزموس للملفات الموزعة).
نظام الملفات FTP: ويقوم هذا النظام بتخزين كافة بياناته على خوادم FTP يمكن الوصول إليها عن بعد.
أنظمة ملفات HTTP و HTTPS القابلة للقراءة فقط.
ويمكن لـ Hadoop العمل مباشرة مع أي نظام ملفات موزع يمكن تركيبه بواسطة نظام التشغيل الأساسي باستخدام ملف (// URL)، ولكن هذا يكون له ثمن، ألا وهو فقدان المحلية. ولتقليل كمية مرور البيانات بالشبكة، يحتاج Hadoop لمعرفة أي خادوم هو الأقرب للبيانات، وهذه هي المعلومات التي يمكن لجسور نظام ملفات Hadoop المخصصة أن توفرها.
وهذا يتضمن Amazon S3 و مخزن الملفات CloudStore، من خلال s3:// و kfs:// URLs مباشرة. هذا وقد كتبت عدد من جسور الطرف الثالث الخاصة بنظام الملفات، ولكن لا يوجد أياً منها حالياً في توزيعات Hadoop.
في عام 2009، ناقشت IBM تشغيل Hadoop عبر نظام ملفات IBM العام المتوازي. وقد تم نشر شفرة المصدر في أكتوبر 2009.
في أبريل 2010، نشرت Parascale شفرة المصدر لتشغيل Hadoop ضد نظام ملفات Parascale.
في أبريل 2010، أطلقت Appistry ناقل حركة لنظام ملفات Hadoop من أجل استخدامه مع منتجات التخزين السحابي الذكية (CloudIQ Storage) الخاصة بها.
في يونيو 2010، ناقشت HP ناقل حركة نظام الملفات IBRIX Fusion.
في مايو 2011، أعلنت شركة MapR Technologies, Inc عن توفر نظام ملفات بديل لـ Hadoop، والذي قام بتبديل نظام ملفات Hadoop الموزع بنظام ملفات كامل الوصول العشوائي للقراءة/الكتابة، مع مميزات متقدمة مثل اللقطات المصورة والملفات البديلة، بالإضافة للتخلص من مشكلة العطل في NameNode الافتراضية لنظام ملفات Hadoop الموزع.
متعقب الوظيفة ومتعقب المهمة: محرك MapReduce
فوق أنظمة الملفات يأتي محرك MapReduce، والذي يتكون من متعقب للوظيفة، ويتم دفع وظائف MapReduce عن طريق تطبيقات العملاء. ويقوم متعقب الوظيفة بدوره بدفع العمل خارجاً إلى عقد متعقب المهمة المتاحة في العنقود، ساعياً للحفاظ على العمل كأقرب ما يكون للبيانات. ومع نظام الملفات الواعي بالرفوف، يكون متعقب الوظيفة على علم بالعقدة التي تحتوي على البيانات، وأي الآلات الأخري التي توجد بالقرب منها. وإذا كان العمل لا يمكن استضافته على العقدة الفعلية حيث توجد البيانات، فإن الأولوية تُعطي للعقد الموجودة على نفس الرف. وهذا يقلل كمية مرور البيانات على العمود الفقري الرئيسي لها. أما إذا فشل متعقب المهمة أو نفذ الوقت، فإن هذا الجزء من المهمة يعاد جدولته. ويقوم متعقب المهمة على كل عقدة بتوليد آلة جافا افتراضية منفصلة لمنع متعقب المهمة نفسه من الفشل إذا قامت المهمة التي ينفذها بتعطيل آلة جافا الافتراضية. وترسل نبضات من متعقب المهمة إلى متعقب الوظيفة كل بضع دقائق للتأكد من حالته. وتستعرض حالات ومعلومات متعقب الوظيفة ومتعقب المهمة من خلال متصفح الويب بواسطة خادوم Jetty.
وإذا فشل متعقب الوظيفة على Hadoop 0.20 أو ما قبله، فإن كل الأعمال الجارية سوف تفقد. وقد أضافت نسخة Hadoop 0.21 بعض نقاط الحفظ لهذه العملية، حيث يقوم متعقب الوظيفة بتسجيل كل ما هو عليه في نظام الملفات. وعندما يبدأ متعقب الوظيفة، يقوم بالبحث عن أياً من هذه البيانات لكي يتمكن من استئناف العمل من النقطة التي توقف عندها. أما في النسخ السابقة من Hadoop، فقد كانت كل الأعمال النشطة تفقد عندما يتم إعادة تشغيل متعقب الوظيفة.
القيود المعروفة لهذا النهج هي:
توزيع العمل على متعقبات المهام هو أمر بسيط. فكل متعقب مهمة يمتلك عدد من المنافذ المتاحة (مثل "4 منافذ"). وتقوم كل مهمة map أو reduce نشطة باحتلال منفذ واحد. ويقوم متعقب الوظيفة بتعيين العمل للمتعقب الأقرب إلى البيانات مع أحد المنافذ المتاحة. ولا يوجد هناك أي اعتبار لحمل النظام الحالي للآلة المُخصصة، وبالتالي للتوافر الفعلي الخاص بها.
إذا كان أحد متعقبي المهام بطيء جداً، فإن ذلك من شأنه تأخير وظيفة MapReduce بأكملها – وخاصة عند نهاية الوظيفة، ففي نهاية المطاف سوف ينتظر كل شيء هذه المهمة البطيئة. وعلي أية حال، فمع تفعيل التنفيذ الفكري، يمكن للمهمة الواحدة أن يتم تنفيذها على عدد من العقد التابعة.
الجدولة
بشكل افتراضي، يقوم Hadoop باستخدام FIFO، و 5 أولويات جدولة اختيارية لجدولة الوظائف من قائمة انتظار العمل. وفي النسخة 0.19 أعيد هيكلة جدولة الوظيفة من متعقب الوظيفة، وإضافة القدرة على استخدام جدولة بديلة (مثل الجدولة الوسطية أو جدولة السعة).
الجدولة الوسطية
لقد طورت الجدولة الوسطية من قبل فيسبوك. والهدف من الجدولة الوسطية هو توفير أوقات استجابة سريعة للوظائف الصغيرة وتوفير جودة خدمة لوظائف الإنتاج. وتمتلك الجدولة الوسطية 3 مفاهيم أساسية:
تجمع الوظائف في وحدات
كل وحدة تحصل على حد أدني مضمون من الحصة المتاحة
تقسم الطاقة الفائضة بين الوظائف.
وبشكل افتراضي، ترسل الوظائف غير المصنفة إلى وحدة افتراضية. ويجب على الوحدات أن تحدد الحد الأدنى من منافذ map، ومنافذ reduce، والحد الخاص بعدد الوظائف النشطة.
جدولة السعة
لقد طورت جدولة السعة من قبل ياهو. وتدعم هذه الجدولة العديد من المميزات التي تشبه الجدولة الوسطية.
تضاف الوظائف في قوائم انتظار
تخصص جزء من إجمالي الطاقة الإنتاجية للموارد من أجل قوائم الانتظار
المصادر الحرة تخصص لقوائم الانتظار خارج إجمالي طاقتها الإنتاجية.
ضمن قوائم الانتظار، سوف تمتلك الوظيفة ذات المستوي العالي من الأولوية إمكانية الدخول إلى موارد قائمة الانتظار.
لا يوجد هناك استباق بمجرد أن تشغل الوظيفة.
التطبيقات الأخرى
لا يقتصر نظام ملفات Hadoop الموزع على وظائف MapReduce فقط. حيث يمكن استخدامه لتطبيقات أخري، العديد منها قيد التطوير حالياً في منظمة Apache. وتتضمن القائمة قاعدة بيانات Hbase، وآلة نظام التعليم Apache Mahout، ونظام تخزين البيانات Apache Hive Data Warehouse. ومن الناحية النظرية، يمكن استخدام Hadoop لأي نوع من الأعمال التي تعتبر كثيفة البيانات بشكل كبير، والقادرة على العمل على قطع من البيانات في نفس الوقت. واعتباراً من أكتوبر 2009، تضمنت التطبيقات التجارية لـ Hadoop:
سجل و/أو تحليل تدفق النقرات لأنواع مختلفة
تحليلات التسويق
تعلم الآلة و/أو استخراج البيانات المتطورة.
معالجة الصور
معالجة رسائل XML
تقدم الويب و/أو معالجة النصوص
الأرشفة العامة، بما في ذلك البيانات العلائقية/الجدولية
المستخدمين البارزين
ياهو
في 19 فبراير 2008، أصدرت شركة ياهو ما أُطلق عليه حينها أكبر تطبيق إنتاج Hadoop في العالم. ويعتبر Search Webmap التابع لشركة ياهو هو أحد تطبيقات Hadoop التي تعمل على أكثر من 10.000 نواة لينكس عنقودية وينتج بيانات تستخدم في كل عملية بحث لياهو على شبكة الأنترنت.
هناك عناقيد متعددة في ياهو، ولا يوجد أنظمة ملفات HDFS أو وظائف MapReduce يتم تقسيمها عبر مراكز بيانات متعددة. فكل عقدة لعنقود Hadoop تمهد صورة لينكس، بما في ذلك توزيعة Hadoop. والعمل الذي تؤديه الكتل يُعرف باحتوائه على قائمة الحسابات الخاصة بمحرك البحث ياهو.
وفي 10 يونيو 2009، أتاحت ياهو شفرة المصدر الخاصة بنسخة Hadoop التي تقوم بإنتاجها للجمهور. وتقوم ياهو بمشاركة كل العمل الذي تقوم به على Hadoop مع المجتمع. كما يقوم مطوري الشركة أيضاً بإصلاح الثغرات وإضافة تحسينات على مستوي الاستقرار الداخلي، وإطلاق هذه الشفرات بحيث يستفيد المستخدمين الآخرين من جهودهم.
فيسبوك
في عام 2010، صرحت شركة فيسبوك بأنها تمتلك أكبر كتلة Hadoop في العالم مع مساحة تخزين 21 بيتابايت. وفي 27 يوليو 2011، أعلنوا أن البيانات قد وصلت إلى 30 بيتابايت. وبعد ذلك في 13 يونيو 2012، قالوا أن حجم البيانات قد نما ليصل إلى 100 بيتا بايت. وأخيراً في 8 نوفمبر 2012، أعلنوا بأن مستودع البيانات أصبح ينمو بنحو نصف بيتابايت يومياً.
المستخدمين الآخرين
بالإضافة لفيسبوك وياهو، هناك العديد من المنظمات الأخري التي تستخدم Hadoop لتشغيل العمليات الحسابية الكبيرة الموزعة. وبعض من هؤلاء المستخدمين البارزين:
Amazon.com
Akamai
American Airlines
AOL
AVG
eBay
Electronic Arts
Hortonworks
Federal Reserve Board of Governors
Foursquare
Fox Interactive Media
Google
Hewlett-Packard
IBM
ImageShack
ISI
InMobi
Intuit
Joost
Last.fm
LinkedIn
NetApp
Netflix
Ooyala
Riot Games
Spotify
Qualtrics
The New York Times
SAP AG
SAS Institute
StumbleUpon
Twitter
Yodlee
Hadoop على خدمات أمازون EC2/S3
من الممكن تشغيل Hadoop على خدمة أمازون المرنة للحوسبة السحابية (EC2) وخدمة أمازون للتخزين البسيط (S3). فعلي سبيل المثال، استخدمت صحيفة نيويورك تايم100 نسخة لخدمة أمازون المرنة للحوسبة السحابية (EC2) وتطبيق Hadoop لمعالجة 4 تيرا بايت من بيانات صور TIFF خام (مخزنة في خدمة أمازون للتخزين البسيط) وتحويلها إلى 11 مليون ملف PDF منتهي في غضون 24 ساعة وبتكلفة حوسبة 240 دولار (لا تشمل الباندويث).
هناك دعم لنظام ملفات خدمة أمازون للتخزين البسيط في توزيعة Hadoop، ويقوم فريق Hadoop بتوليد نسخة خاصة لخدمة أمازون المرنة للحوسبة السحابية بعد كل إصدار. ومن منظور الأداء البحت، فإن Hadoop على خدمة أمازون المرنة للحوسبة السحابية وخدمة أمازون للتخزين البسيط يعتبر غير فعال، حيث أن نظام أمازون للتخزين البسيط يعمل عن بعد ويأخر العودة من كل عملية كتابة حتي يتم ضمان عدم فقدان البيانات. وهذا من شأنه إزالة مزايا مركزية Hadoop، والتي تقوم بجدولة العمل بالقرب من البيانات لتوفير حمل الشبكة.
إطار MapReduce لخدمة أمازون المرنة
لقد قدم Elastic MapReduce بواسطة أمازون في أبريل 2009. هذا وتزود كتلة Hadoop بالمؤن اللازمة لها، وتشغيل وإنهاء الوظائف، والتعامل مع نقل البيانات بين خدمة أمازون المرنة للحوسبة السحابية وخدمة أمازون للتخزين البسيط بشكل أتوماتيكي عن طريق Elastic MapReduce. كما تقدم Apache Hive، التي بنيت فوق Hadoop لتوفير خدمات مستودع البيانات من قبل Elastic MapReduce كذلك.
وقد أضيف الدعم لاستخدام نماذج النقاط (Spot Instances) لاحقا في أغسطس 2011. كما أن Elastic MapReduce قادر على تحمل إخفافات التابعين، وينصح بتشغيل مجموعة المهمة فقط على نماذج النقاط للاستفادة من التكلفة المنخفضة مع الحفاظ على التوافر.
وفي يونيو 2012، أضيفت خيارات متميزة لإطار Elastic MapReduce والتي تستبدل نسخة Hadoop العادية بنسخ MapR M3 و M5. وهذه الخيارات توفر قدرات إضافية فوق ما يقدمه إطار Elastic MapReduce الافتراضي.
دعم الصناعة للمجموعات الأكاديمية
أعلنت IBM وجوجل عن مبادرة في عام 2007 لاستخدام Hadoop لدعم الدراسات الجامعية في مجال برمجة الحاسب الموزعة. وفي عام 2008، قام هذا التعاون (مبادرة الحوسبة السحابية الأكاديمية) بالشراكة مع المؤسسة الوطنية للعلوم من أجل توفير التمويل اللازم للباحثين الأكاديميين المهتمين باكتشاف تطبيقات البيانات الضخمة. وقد أدي هذا لإنشاء برنامج الكتلة الاستكشافية (CLuE).
تشغيل Hadoop في بيئة حقول الحوسبة
يمكن استخدام Hadoop أيضاً في حقول الحوسبة وبيئات الحوسبة عالية الأداء. وبدلاً من إعداد كتلة Hadoop مخصصة، يمكن أن يستخدم حقل الحوسبة القائم إذا كان مدير موارد الكتلة على دراية بوظائف Hadoop، وبالتالي يمكن جدولة وظائف Hadoop مثل الوظائف الأخري الموجودة في الكتلة.
تكامل محرك الشبكة
أطلقت عملية التكامل مع محرك Sun Grid Engine عام 2008، وبذلك أصبح من الممكن تشغيل Hadoop على Sun Grid (خدمة حوسبة حسب الطلب). وفي مرحلة التطبيق الأولي للتكامل، كانت جدولة وقت وحدة المعالجة المركزية ليس لديها علم بمركزية البيانات. ولسوء الحظ، هذا يعني أن المعالجة لا تتم دائما على نفس الرف مثل البيانات، وهذه كانت إحدى السمات الرئيسية لإطار Hadoop Runtime، والذي يعتبر تكامل مُحسن على دارية بمركزية البيانات والذي أعلن عنه أثناء ورشة برمجيات Sun HPC '09.
وفي الفترة ما بين 2008-2009، أطلقت شركة Sun مشروع Hadoop Live CD OpenSolaris، والذي يسمح بتشغيل عنقود Hadoop عاملة بالكامل باستخدام قرص مباشر. وهذه التوزيعة تشمل Hadoop 0.19، واعتبارا من أبريل 2010 لم يطلق أية تحديث لهذه التوزيعة.
تكامل كوندور
قدم تكامل نظام حوسبة كوندور ذو الإنتاجية العالية في مؤتمر Condor Week عام 2010.
منتجات Hadoop التجارية المدعومة
هناك عدد من الشركات التي تقدم تطبيقات تجارية و/أو توفر الدعم لـ Hadoop
تقوم شركة Cloudera بتقديم CDH (توزيعة Cloudera التي تتضمن Apache Hadoop) ومؤسسة Cloudera.
تقدم شركة IBM مشروع WebSphere eXtreme Scale (المعروف سابقاً باسم ObjectGrid) والذي يتضمن نمطين من أنماط HADOOP MapReduce في "وكلائهم" الملقبين بواجهة DataGrid. جنباً إلى جنب مع قدرة التخزين المؤقت للبيانات الموزعة، كما أنه يمنح كلا من map و reduce القدرة على موازاة الوظيفة وتخزين كمية كبيرة من البيانات (في الذاكرة) لتسهيل عملية دخول الوظيفة إليها.
تقوم IBM بتقديم InfoSphere BigInsights والمعتمد على Hadoop في نسخته الأساسية ونسخته الخاصة بالمشاريع.
أما شركة Talend فتقدم Talend Open Studio للبيانات الضخمة، والذي أُطلق تحت رخصة برمجيات أباتشي، ويتضمن دعم أصلي لـ Apache Hadoop.
وتقوم WANdisco بتقديم WDD (توزيعة WANdisco التي تتضمن Apache Hadoop)
وتقدم شركة Zettaset نسخة جديدة من منصة Mgt للبيانات الضخمة والمعتمدة على Hadoop. وتقوم منصة Zettaset بتوفير إتاحة عالية النطاق عن طريق خادوم NameNode Failover، وواجهة مستخدم مبسطة، بالإضافة لبروتوكول وقت الشبكة ونظام أمان داخلي عن طريق مصادقة Kerberos.
وفي مايو 2010، أعلنت شركة Pentaho عن دعمها لمنصة Apache Hadoop مما يسمح للشركات بالوصول إلى تكامل البيانات وتحليلات الأعمال مباشرة ضد التوزيعات المعتمدة على Apache Hadoop. وفي يناير 2012، أعلنت Pentaho أنها جعلت قدرات تكامل البيانات الضخمة الخاصة بهم متاحة مجاناً في إطار مفتوح المصدر، ونقلت مشروع Pentaho Kettle (محرك تكامل البيانات) بالكامل من رخصة LGPL إلى رخصة أباتشي.
وفي مارس 2011، أعلنت Platform Computing (اشترتها شركة IBM لاحقا ) عن دعمها لواجهة تطبيقات Hadoop MapReduce في برنامجها Symphony.
وفي مايو 2011، أعلنت شركة MapR Technologies, Inc. عن توافر نظام ملفاتهم الموزع ومحرك MapReduce والذي يعتبر توزيعة MapR الخاصة بـ Apache Hadoop. ويتضمن منتج MapR معظم مكونات النظام البيئي الخاصة بـ Hadoop ويضيف إلى ذلك قدرات ومميزات أخري مثل اللقطات المصورة، النسخ، وصول NFS، والقراءة والكتابة الكاملة لدلالات الملفات. وقد اختيرت توزيعة MapR من قبل أمازون لتوفير النسخ المدفوعة من خدمة Elastic Map Reduce.
أما شركة Silicon Graphics International فتوفر حلول Hadoop المخصصة بالاعتماد على خطوط خوادم SGI Rackable و CloudRack بالإضافة لخدمات التنفيذ.
قامت شركة EMC بإصدار EMC Greenplum نسخة المجتمع و EMC Greenplum HD نسخة الشركات في مايو 2011. وتأتي نسخة المجتمع مع دعم فني اختياري مقابل بعض الرسوم، وتتكون من Hadoop، نظام ملفات Hadoop الموزع، Hbase، Hive وخدمة تكوين ZooKeeper. أما نسخة الشركات فتُعرض للبيع بالاستناد على منتجات MapR، وتوفر مميزات بريميوم مثل اللقطات المصورة والتكرار.
وفي يونيو 2011، أسست ياهو بالتعاون مع Benchmark Capital شركة جديدة أطلق عليها Hortonworks Inc والتي تركز على جعل Hadoop أكثر قوة وأسهل من ناحية التثبيت والإدارة والاستخدام في المؤسسات والشركات.
أضافت جوجل محرك التطبيقات MapReduce لدعم تشغيل برامج Hadoop 0.20 على محرك تطبيقات جوجل.
في أكتوبر 2011، أعلنت أوراكل عن جهاز البيانات الضخمة (Big Data Appliance) والذي يدمج توزيعة Cloudera (CDH)، و Oracle Enterprise Linux، ولغة البرمجة R، وقاعدة البيانات NoSQL مع أجهزة إكسا داتا.
إن إدارة OceanSync Hadoop وبرمجيات التصور تتيح للمستخدم التحكم، ورصد ووضع تصور لجميع جوانب كتلة Hadoop بما فيها إدارة البيانات التحليلية لسير العمل وتصور معالجة إخراج البيانات. وتتوفر هذه الحزمة في ثلاثة إصدارات، نسخة OceanSync المجانية لسطح المكتب، نسخة OceanSync للشركات، ونسخة OceanSync Mobile لأجهزة الآيفون والأندرويد.
أما منتج JobServer التابع لشركة Grand Logic فيسمح للمطورين والمدراء بنشر، وإدارة ومراقبة بنيتهم التحتية الخاصة بـ Hadoop – مع دعم لمعالجة وظيفة Hadoop وإدارة ملفات/محتويات نظام ملفات Hadoop الموزع.
قامت شركة Dell بإضافة تحليلات الأعمال Pentaho إلى حلول Dell Apache Hadoop الخاصة بتحليلات البيانات الضخمة والتي تتكون من خوادم Dell، ومكونات شبكات Dell، وإطار Dell Crowbar للبرمجيات السحابية مفتوحة المصدر، وتوزيعة Cloudera (CDH).
أما مايكروسوفت فتقدم استعراض المطورين لـ HDInsight والتي تتوافق 100% مع توزيعة Hadoop.
في فبراير 2013، أطلقت إنتل توزيعة Hadoop الخاصة بها، والتي تستفيد من القدرات الموجودة في رقائق Intel Xeon مثل تعليمات المعالج الخاصة بها من أجل تسريع تشفير AES.
وتقدم شركة Splunk منتجا متكاملا مع Hadoop يُدعي Hadoop Connect، والذي يعتمد على MapR، Cloudera، Hortonworks و Apache Hadoop. وهذا التكامل يتيح للمستخدم البحث عن بيانات Hadoop من Splunk واستيراد البيانات من Hadoop إلى Splunk والعكس.
رأي مؤسسة أباتشي للبرمجيات حول استخدام "Hadoop" في أسماء المنتجات
صرحت مؤسسة أباتشي للبرمجيات أن البرامج التي صدرت رسميا من مشروع Apache Hadoop هي الوحيدة التي يمكن أن يُطلق عليها Apache Hadoop أو توزيعات Apache Hadoop. أما تسمية المنتجات والأعمال المشتقة من الشركات الأخري وإطلاق مصطلح "متوافقة" عليها، هو أمر مثير للجدل إلى حد ما ضمن مجتمع مطوري Hadoop
الأبحاث
بعض الأبحاث التي أثرت على ولادة ونمو Hadoop ومعالجة البيانات الضخمة. فيما يلي بعض من هذه اللائحة:
عام 2004، MapReduce: Simplified Data Processing on Large Clusters بواسطة جيفري دين وسانجاي جيموات من مختبر جوجل. هذا البحث ألهم دوغ كاتينغ لتطوير تطبيق مفتوح المصدر لإطار Map-Reduce والذي أطلق عليه Hadoop تيمناً بالفيل اللعبة الخاص بابنه.
عام 2005، From Databases to Dataspaces: A New Abstraction for Information Management – قام الكاتب بتسليط الضوء على الحاجة لأنظمة التخزين لقبول جميع صيغ البيانات وتوفير واجهات برمجة من أجل الوصول إلى البيانات التي تتطور على أساس فهم نظام التخزين للبيانات.
عام 2006، Bigtable: A Distributed Storage System for Structured Data – من مختبر جوجل.
عام 2008، H-store: a high-performance, distributed main memory transaction processing system
عام 2011، Apache Hadoop Goes Realtime at Facebook
مقالات أخرى حول تقنيات الحوسبة السحابية إذا كنت مهتما:
نظرة معمقة على الحاسوب العملاق supercomputer
ماذا تعرف عن حوسبة كثيفة البيانات Data-intensive computing؟
ماذا تعرف عن البيانات الضخمة Big Data ؟
معلومات حول المقالة:
هذه المقالة مترجمة من موسوعة ويكيبديا بعنوان Apache Hadoop. ترجمة محمد مصباح و مراجعة فهد السعيدي، هذه المقالة قد تحوي على أخطاء فإذا لاحظت شيئا منها، يرجى مراسلتنا حتى نقوم بإصلاحها.